
En mars 2022, une vidéo circule sur Internet. On y voit le président ukrainien Volodymyr Zelensky appeler ses compatriotes à poser les armes, à se rendre, à ne plus sacrifier leur vie pour une guerre qui n'en vaudrait pas le coup. Le problème : Zelensky n'a jamais dit ça. <cite index="13-3">Le 16 mars 2022, une vidéo truquée de type deepfake a été publiée sur les réseaux sociaux et placée sur le site web de la chaîne d'informations Ukraine 24 par des hackers.</cite> C'est le premier deepfake utilisé dans un conflit armé à grande échelle. Et il était raté. Pas un peu raté. Franchement raté.
Ma première réaction a été de penser : "Et dire qu'on nous présente les hackers russes comme les meilleurs du monde." Mais cette réaction, je l'ai vite nuancée. Parce que réaliser un bon deepfake est beaucoup plus difficile qu'il n'y paraît. Et les raisons pour lesquelles celui-ci a échoué sont exactement les mêmes raisons pour lesquelles les projets IA échouent dans les entreprises. Pas dans les films. Dans la vraie vie, chez vos équipes data, dans vos projets SaaS, sur vos roadmaps produit.
Ce que la vidéo montrait concrètement
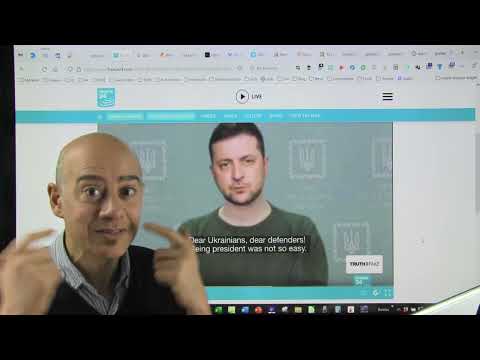
<cite index="18-9,18-10,18-11">Ce mercredi 16 mars, la chaîne Ukraine 24 a publié un post indiquant que sa diffusion en direct ainsi que son site Internet avaient été hackés. Peu de temps avant, une vidéo très surprenante du président Zelensky avait été diffusée, dans laquelle il déclarait notamment "rendre le Donbass" et appelait les Ukrainiens à "rendre les armes" et à retrouver leurs familles, avant d'annoncer quitter son poste.</cite>
La réaction de Zelensky a été immédiate. <cite index="19-7">En quelques minutes, une vraie vidéo de réponse du président a été enregistrée et diffusée sur les réseaux sociaux.</cite> <cite index="16-6">Ce deepfake se distingue des autres grands exemples de la technologie dans ce conflit par le fait qu'il est suggéré que l'audio ait également été généré via l'IA.</cite> Autrement dit, les auteurs ont attaqué sur deux fronts simultanément : le visage et la voix. Et ils ont raté les deux.
Quand je regarde cette vidéo image par image, les défauts sautent aux yeux. La texture du visage est ostensiblement synthétique. Le visage est encore plus statique que dans les vraies vidéos de Zelensky. Il y a un gros effet de flou au niveau de la jonction du cou avec le buste. Et la différence de teinte de peau entre le visage et le reste du corps est visible à l'oeil nu. <cite index="18-20,18-21">Dans le cas du deepfake de Zelensky, il était plutôt facile de se rendre compte qu'il ne s'agissait pas d'une vidéo réelle : sa tête semblait avoir été collée sur une photo fixe de son corps, et bien que son visage bouge de façon assez convaincante, il bouge de manière peu naturelle, tandis que sa voix est bien plus profonde que sa voix réelle.</cite>
Comment fonctionne un deepfake, techniquement
Pour comprendre pourquoi ce deepfake était raté, il faut d'abord comprendre comment on en fabrique un.
La première étape consiste à télécharger un logiciel spécialisé. Il en existe plusieurs en open source, dont <cite index="7-18">des outils comme DeepFaceLab, FaceSwap, et Synthesia qui rendent la création de deepfakes accessible même aux non-experts.</cite> On lui fournit ensuite une base de données vidéo de la personne à imiter, en l'occurrence Zelensky. Le logiciel décompose ces vidéos quasiment image par image. Sur des dizaines ou des centaines d'images, il apprend à identifier les caractéristiques du visage : les yeux, la bouche, le nez, les expressions, les variations d'ouverture de la bouche.
Ensuite, on tourne une vidéo d'un acteur qui va prononcer le texte que l'on veut faire dire à Zelensky. Là encore, le logiciel analyse ce visage d'acteur : où sont ses yeux, comment sa bouche se déplace quand il parle, quelles sont ses expressions. <cite index="25-9,25-10">Le modèle est alors entraîné à aligner et à transformer les visages de manière à correspondre au mieux aux visages cibles, via des algorithmes d'alignement facial et des techniques de normalisation pour assurer une cohérence spatiale et une apparence réaliste.</cite>
La dernière étape : on fournit la vidéo de l'acteur, et le logiciel superpose les traits du visage de Zelensky sur ceux de l'acteur, en adaptant les variations en temps réel : bouche ouverte, bouche fermée, regard à gauche, sourire, etc. La vidéo deepfake est générée. <cite index="12-33,12-34">Les deepfakes sont générés à l'aide de deux réseaux de neurones artificiels entraînés conjointement : le premier est un générateur, qui produit des images ou vidéos synthétiques, et le second, un discriminateur, qui apprend à distinguer ces contenus générés des exemples authentiques.</cite>
Et à la fin, on doit faire la même chose pour la voix. C'est une couche entière de travail supplémentaire. Je l'ai gardée pour la fin de cet article parce que j'ai moi-même failli l'oublier au moment de la préparer. Mais on y revient.
Pourquoi ce deepfake était techniquement raté
La vraie question n'est pas "pourquoi les hackers ont-ils créé ce deepfake" mais "pourquoi était-il si mauvais".
Ma réponse : pour les mêmes raisons exactement pour lesquelles la plupart des projets IA en entreprise sous-performent. Les données. La qualité des données. La puissance de calcul. Le temps d'entraînement.
Je pense que le logiciel deepfake a extrait quelques centaines d'images à partir des vidéos de Zelensky disponibles en ligne, là où il aurait fallu plusieurs milliers d'images pour produire un résultat de bonne facture. <cite index="26-2,26-3">Les performances du Deep Learning continuent de s'améliorer au fur et à mesure que la taille des données d'apprentissage augmente. Généralement, le Deep Learning nécessite une très grande quantité de données, par exemple des milliers d'images dans le cas de la classification d'images, pour entraîner le modèle.</cite>
Ensuite, la qualité des vidéos sources. Si les auteurs ont récupéré des extraits vidéo en MPEG très compressé, en basse résolution, là où il leur aurait fallu de la HD propre, le résultat sera nécessairement dégradé. <cite index="21-6,21-7,21-8">La qualité des données est cruciale et peut compenser la quantité pour certains modèles IA. La variabilité correspond à la diversité et à la portée des données disponibles : plus les données sont variées, plus le modèle peut apprendre et généraliser efficacement.</cite>
Troisième facteur probable : la puissance de calcul. Si les auteurs ont utilisé une machine de gamer avec une carte graphique de puissance moyenne, les cycles d'entraînement s'allongent considérablement. On parle peut-être de 20 à 24 heures par itération. <cite index="26-4">L'accès à des GPU hautes performances peut réduire considérablement le temps d'apprentissage.</cite> <cite index="25-15,25-16,25-17">L'entraînement n'est pas limité dans le temps : plus le temps passe, plus le modèle devient précis. Plus le score affiché est petit, plus le deepfake sera précis.</cite> Si les auteurs n'ont eu le temps que de réaliser trois ou quatre itérations au lieu de trente ou quarante, le résultat sera pixelisé, avec des zones clairement synthétiques visibles à l'oeil nu.
Il y a aussi la question de la représentativité des données. Pour que le modèle apprenne correctement à imiter Zelensky, il lui faut des vidéos où le président regarde dans différentes directions, prononce un maximum de phonèmes différents, adopte des expressions variées. Si le dataset ne couvre pas suffisamment ces variations, le visage généré sera rigide, statique, peu naturel. C'est exactement ce que j'observe dans cette vidéo.
Le calcul probabiliste derrière ce deepfake raté
Il y a un point que je ne veux pas esquiver : je ne pense pas que les auteurs ignoraient que leur deepfake était imparfait. Je pense qu'ils ont fait un calcul.
Leur hypothèse : beaucoup d'Ukrainiens regarderaient cette vidéo sur un téléphone mobile, probablement en 3G ou avec une connexion lente. Sur un petit écran, en basse résolution, les artefacts deviennent beaucoup moins visibles. Les zones synthétiques se fondent dans les artefacts de compression naturels d'une vidéo mobile. La jonction floue entre le visage et le cou passe pour une mauvaise qualité d'encodage.
C'est un pari sur la qualité de la chaîne de diffusion et sur l'attention des spectateurs. <cite index="19-8">La mauvaise qualité du deepfake, la rapidité avec laquelle il a été détecté et réfuté, ainsi que la capacité à diffuser la vraie vidéo via une connexion Internet largement stable ont tous contribué à l'échec de ce faux appel à la reddition.</cite> Ce n'était pas un pari anodin : <cite index="8-5">cette vidéo a rapidement été identifiée comme un deepfake à cause de sa faible qualité et n'a donc eu que peu de répercussions sur les combats, mais cet exemple illustre parfaitement les dangers que peuvent poser les deepfakes.</cite>
L'accessibilité des outils ne garantit pas la qualité du résultat
On entend souvent dire que "n'importe qui peut créer un deepfake". C'est vrai, et c'est faux en même temps.
C'est vrai dans le sens où les outils existent. <cite index="4-7">Les outils permettant de créer des deepfakes sont déjà à la portée de n'importe qui.</cite> Il existe des logiciels open source téléchargeables gratuitement, des services SaaS no-code payants qui génèrent des deepfakes pour une soixantaine d'euros. Pas besoin d'un supercalculateur du Pentagone ou d'un accès aux serveurs du FSB.
Mais c'est faux dans le sens où créer un deepfake convaincant exige cinq conditions que peu de gens réunissent simultanément. Premièrement, une bonne maîtrise technique du logiciel, car ces outils ne s'optimisent pas seuls. Deuxièmement, des vidéos sources en grande quantité. Troisièmement, des vidéos sources de bonne qualité, idéalement en HD. Quatrièmement, des données représentatives : suffisamment d'expressions différentes, suffisamment de phonèmes, suffisamment d'angles de vue. Cinquièmement, du temps pour réaliser les itérations successives d'entraînement jusqu'à obtenir un résultat satisfaisant.
C'est d'ailleurs la même logique que pour un chatbot, un modèle de prévision des ventes ou un algorithme de prédiction du churn. Il existe des outils no-code pour tout ça. Mais un modèle IA de mauvaise qualité, c'est pire qu'un tableur Excel, parce qu'il donne l'illusion de la précision tout en produisant des résultats non fiables. <cite index="12-22,12-23,12-24">Fabriquer un deepfake réellement convaincant reste un exercice exigeant. Il faut du temps, une carte graphique puissante et de nombreuses données. Les contenus générés trop rapidement présentent souvent des défauts visibles : clignements d'yeux irréguliers, ombres incohérentes, expressions rigides ou artefacts numériques.</cite>
La donnée : le vrai goulot d'étranglement de tout projet IA
Ce deepfake raté illustre de façon spectaculaire ce que je répète aux PME et aux startups que j'accompagne : le vrai problème dans un projet IA n'est presque jamais l'algorithme. C'est la donnée.
On a tendance à surestimer l'importance du modèle et à sous-estimer celle des données qui l'alimentent. Pourtant, la logique est invariable, que l'on parle d'un deepfake ou d'un modèle prédictif pour une plateforme e-commerce. Si la donnée source est compressée, partielle, non représentative ou trop peu volumineuse, le modèle apprendra mal. Et si le modèle apprend mal, le résultat final sera décevant, peu importe la sophistication de l'architecture.
<cite index="28-20,28-21,28-22">Un réseau ayant pour unique tâche de reconnaître des chats devra être entraîné avec des milliers de photos avant de pouvoir discerner cet animal d'une autre entité avec une bonne précision. Plus le jeu de données d'apprentissage est important, meilleure sera la précision de l'algorithme. Cette contrainte n'est pas négligeable car il est difficile, voire parfois impossible, de collecter des quantités aussi importantes de données.</cite>
Dans mon travail avec les entreprises, je vois exactement ce schéma se répéter. Une équipe décide d'intégrer de l'IA dans son processus. Elle choisit un bon outil, elle a un cas d'usage clair. Mais elle part avec six mois de données transactionnelles là où le modèle en demanderait trois ans. Ou avec des données mal étiquetées. Ou avec une saisonnalité non représentée dans la période de collecte. Le résultat est décevant. L'équipe conclut que "l'IA ne fonctionne pas". Ce n'est pas l'IA qui ne fonctionne pas. C'est la donnée.
La voix : la couche oubliée du deepfake
Je voulais finir sur un point que j'aurais failli passer sous silence, et qui illustre parfaitement la complexité réelle de ce type de projet.
Quand on produit un deepfake, il ne suffit pas de remplacer le visage. Il faut également cloner ou synthétiser la voix. C'est une deuxième couche de travail complète, indépendante du travail sur le visage, avec ses propres exigences en termes de données sources, de qualité audio, de temps d'entraînement, de réglages fins.
<cite index="2-19,2-20">Une étude publiée dans PLOS One révèle que les humains ne détectent les deepfakes audio qu'avec 73 % de précision. Autrement dit, 1 personne sur 4 se fait duper par le clonage vocal.</cite> Dans le cas du deepfake de Zelensky, <cite index="13-15">la synchronisation des lèvres était relativement crédible, mais les internautes ont rapidement remarqué que l'accent ne correspondait pas et que la voix ne semblait pas authentique.</cite>
C'est un rappel important pour quiconque travaille sur des projets IA multi-couches. Chaque couche supplémentaire multiplie les contraintes de données et d'entraînement. Chaque couche est un nouveau point de défaillance potentiel. Et chaque couche exige ses propres compétences techniques, ses propres données, ses propres cycles d'itération.
Ce que cela change pour vous
Le deepfake de Zelensky n'était pas la démonstration que les hackers russes sont incompétents. C'était la démonstration que la réalité d'un projet IA est toujours plus complexe que ce qu'on imagine depuis l'extérieur.
<cite index="2-1">Le volume de vidéos deepfake en ligne est passé de 500 000 en 2023 à une projection de 8 millions en 2025.</cite> Les outils progressent. Les modèles s'améliorent. <cite index="1-8">Les images générées par IA sont devenues si réalistes qu'il est maintenant presque impossible de distinguer une image fausse d'une image réelle.</cite> Ce qui était détectable à l'oeil nu en 2022 ne l'est plus forcément aujourd'hui.
Mais les fondamentaux, eux, ne changent pas. Qualité de la donnée. Quantité de la donnée. Représentativité. Puissance de calcul. Temps d'entraînement. Maîtrise technique du pipeline complet. Ce sont ces cinq variables qui déterminent si un projet IA livre ou s'effondre, que ce projet soit un deepfake de propagande, un modèle de scoring client, ou un algorithme de recommandation produit.
Si vous êtes en train de construire ou d'évaluer un projet IA dans votre organisation, c'est exactement sur ces variables que je peux vous aider à poser les bonnes questions avant de dépenser votre budget. Contactez-moi via nachnouchi.com pour une première consultation.
